
- A+


如何在有限的时间和资源下继续取得惊人的成果,
编写有教育性和说服力的高质量内容仍然是实现流量和转换目标的可靠方法。
但这个过程是一项艰巨的手工工作,无法扩展。
幸运的是,自然语言理解和生成的最新进展提供了一些有希望和令人兴奋的结果。
在他的SEJ eSummit会议上,Hamlet Batista讨论了目前可能的情况,使用了一些实际例子(和代码),技术SEO专业人员可以遵循并适应他们的业务。
下面是他的演讲的摘要。

自动完成建议
你遇到过多少次这种情况,
你开始在Gmail上输入,Google会自动完成整个部分,而且非常准确。
你知道,这真的很吸引人,但同时,它也可能非常可怕。
你可能已经在你的工作中使用了人工智能技术,而你却没有意识到。
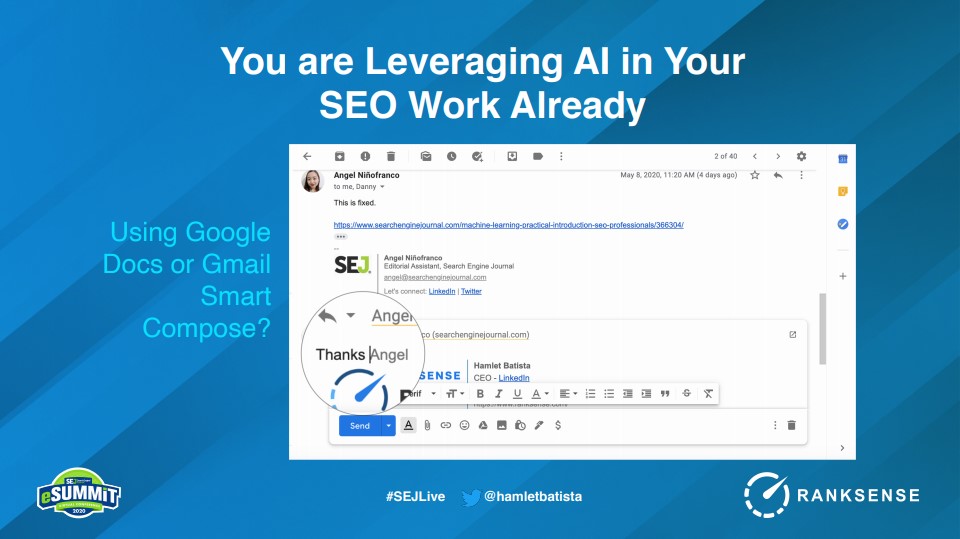
如果你正在使用googledocs的智能撰写功能,Gmail,甚至是microsoftword和Outlook,你已经在利用这项技术了。
作为一名营销人员,这是你与客户沟通的一天中的一部分。
最棒的是,这项技术不仅仅是谷歌可以使用的。
查看Write With Transformer网站,开始打字,点击tab键获取完整句子的想法。
Batista演示了在插入SEJ最近一篇文章的标题和一个句子后,机器可以开始生成行——您只需要点击autocomplete命令。

上面所有突出显示的文本都是由计算机生成的。
最酷的是,让这成为可能的技术是免费的,任何人都可以使用它。
基于意图的搜索
我们现在在SEO中看到的一个转变是向基于意图的搜索的过渡。
正如Mindy Weinstein在她的《搜索引擎杂志》文章中所说的,如何更深入地进行关键词研究:
“我们所处的时代,基于意图的搜索对我们来说比单纯的数量更重要。”
“您应该采取额外的步骤来了解客户提出的问题以及他们如何描述他们的问题。”
“从关键字转到问题”
这种变化给我们在写内容时带来了一个机会。
机会
如今,搜索引擎正在回答引擎的问题。
写原创和流行内容的一个有效方法就是回答目标受众最重要的问题。
看看这个查询“pythonforseo”的例子。
第一个结果表明,我们可以利用回答问题的内容,在本例中使用FAQ模式。
FAQ搜索片段会在SERP中获取更多不动产。

但是,对于要创建的每一部分内容手动执行此操作可能会花费大量时间。
但是如果我们能够利用人工智能和现有的内容资产来实现自动化呢,
利用现有知识
大多数老牌企业已经拥有了宝贵的专有知识库,这些知识库是通过与客户的正常互动而逐渐发展起来的。
很多时候这些还没有公开(支持电子邮件、聊天、内部wiki)。
开源人工智能+专有知识
通过一种称为“转移学习”的技术,我们可以通过结合专有知识库和公共深度学习模型和数据集来生成原创的、高质量的内容。
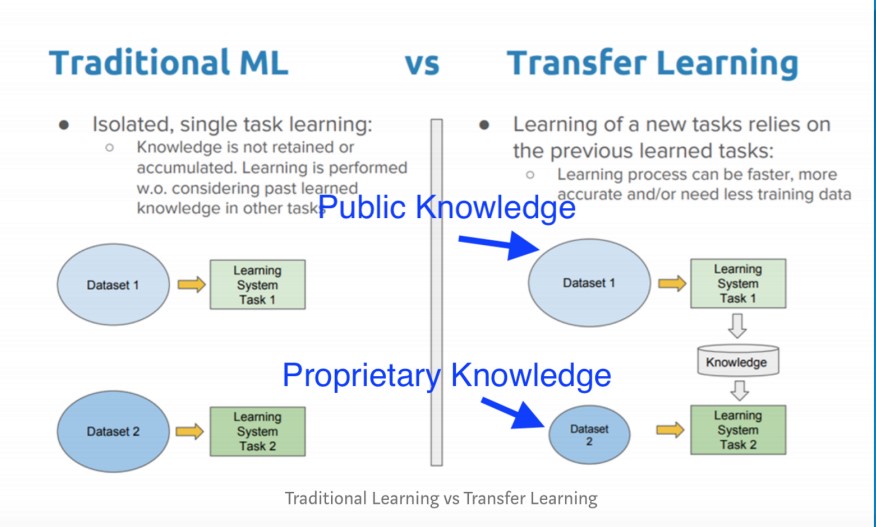
传统的机器学习(ML)和深度学习(deep)有很大的不同。
在传统的ML中,您主要是进行分类,并利用现有的知识得出预测。
现在,通过深入学习,你可以利用一些常识性的深圳谷歌优化知识,这些知识是由谷歌、Facebook、微软等大公司长期积累而成的。
在会议期间,巴蒂斯塔展示了如何做到这一点。
如何自动生成内容
以下是审查自动问答生成方法时要采取的步骤。
- 使用在线工具寻找热门问题
- 使用两种NLG方法回答:
- 跨度搜索法
- 一种“闭门造车”的方法
- 添加FAQ模式并使用SDTT进行验证
寻找热门问题
根据你的关键词找到流行的问题并不是一个很大的挑战,因为有免费的工具可以用来做到这一点。
回答公众
只要输入一个关键字,你就可以得到大量的问题,用户正在问。

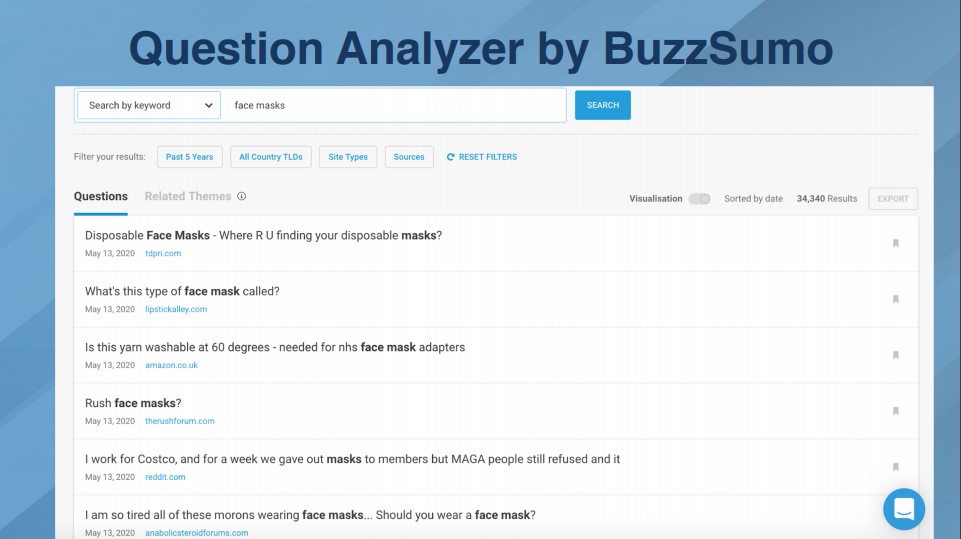
BuzzSumo的问题分析器
他们从论坛和其他地方收集信息。你也可以找到更多的长尾型问题。
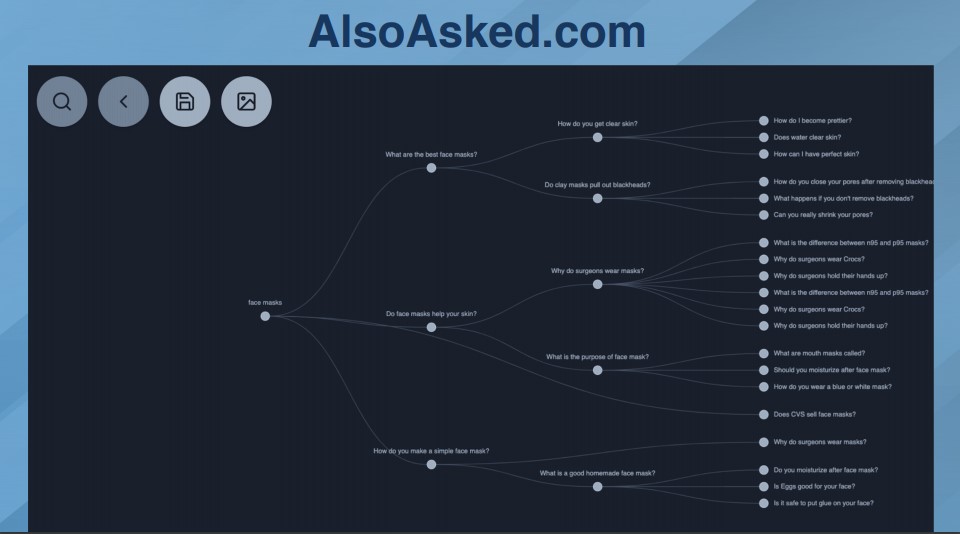
AlsoAsked.com网站
这个工具可以让人们从谷歌那里问问题。
问答系统
算法
带代码的论文是有关问答的前沿研究的重要来源。
它可以让你自由地进入最新的研究,正在发表。
学者和研究人员发布他们的研究成果,这样他们就可以从同行那里得到反馈。
他们总是互相挑战,想出更好的系统。
更有趣的是,即使像我们这样的人也可以访问我们回答问题所需的代码。
对于这个任务,我们将使用T5,或文本到文本传输转换器。
数据集
我们还需要系统将用来学习回答问题的训练数据。
斯坦福问答数据集2.0(班2.0)是最流行的阅读理解数据集。
现在我们已经有了数据集和代码,让我们来讨论一下可以使用的两种方法。
- 开卷答疑:你知道答案在哪里
- 闭书答疑:你不知道答案在哪里
方法1:Span搜索法(开卷)
通过三行简单的代码,我们可以让系统回答我们的问题。
这是你可以在googlecolab中做的事情。
创建一个Colab笔记本并键入以下内容:
当你输入命令时——提供一个问题,以及你认为有问题答案的上下文——你会看到系统基本上在搜索有答案的字符串。
“变形金刚”,
“结束”:59,
“分数”:0.5135626548884602,
“开始”:35}
步骤很简单:
- 加载Transformers NLP库
- 分配一个问答管道
- 提供问题和背景(最有可能包括答案的内容/文本)
那么你要如何获得背景信息,
只有几行代码。
使用requesthtml库,您可以提取URL(相当于将浏览器导航到URL)并提供选择器(这是页面上文本块元素的路径)
我应该简单地打一个电话来提取内容并将其添加到文本中,这就成了我的上下文。
在这个例子中,我们要问一个问题,这个问题包含在SEJ的一篇文章中。
这意味着我们知道答案在哪里。我们提供了一篇有答案的文章。
但是如果我们不知道哪篇文章包含了答案,那我们要问的是,
方法2:用T5&Turing NLG(闭式帐簿)探索NLG的局限性
谷歌的T5(110亿参数模型)和微软的图灵(170亿参数模型)能够在不提供任何上下文的情况下回答问题。
它们是如此巨大,以至于它们能够记住训练时的很多事情。
谷歌的T5团队在一次酒吧琐事挑战赛中与110亿参数模型正面交锋,最终失败。
让我们看看训练T5回答我们自己的任意问题有多简单。
在这个例子中,巴蒂斯塔问的问题之一是“谁是世界上最好的搜索引擎优化”
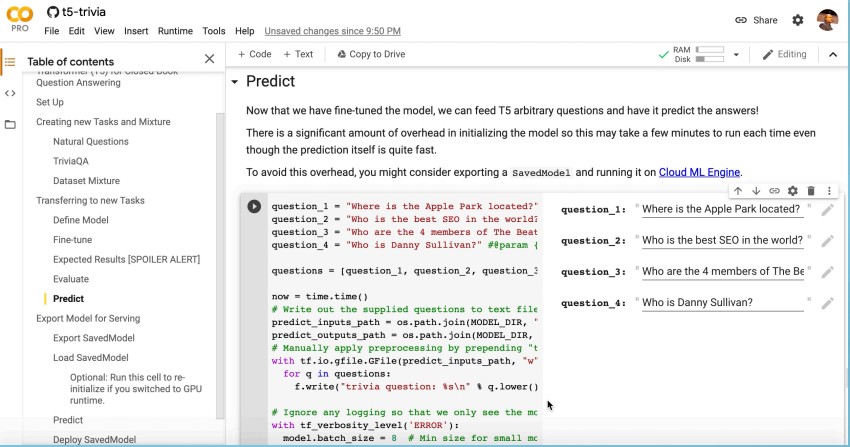
根据谷歌培训的一个模型,世界上最好的搜索引擎优化是SEOmoz。
如何培训、微调和利用T5
培训T5
我们将使用免费的googlecolab TPU训练30亿参数模型。
以下是使用T5的技术方案:
- 将示例Colab笔记本复制到Google驱动器
- 将运行时环境更改为Cloud TPU
- 创建一个Google云存储桶(使用免费的$300信用额度)
- 提供笔记本的存储桶路径
- 选择30亿参数模型
- 剩下的细胞继续进行预测
现在你有了一个可以回答问题的模型。
但我们如何添加您的专有知识,以便它能够从您的网站回答您所在领域或行业的问题,
添加新的专有培训数据集
这就是我们进入微调步骤的地方。
只需单击模型中的微调选项。
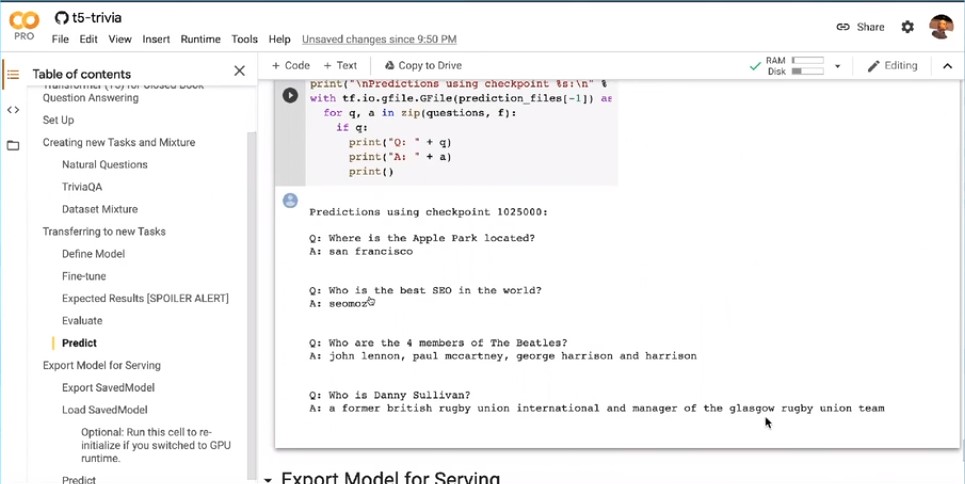
代码中有一些例子说明了如何创建新功能以及如何为模型提供新功能。
记住:
- 将您的专有知识库预处理为可与T5一起使用的格式
- 为此目的修改现有代码(自然问题,TriviaQA)
要了解机器学习的提取、转换和加载过程,请阅读Batista的搜索引擎期刊深圳谷歌推广文章,这是一篇面向SEO专业人士的机器学习实用介绍。
添加常见问题模式
这一步是直截了当的。
只需访问Google文档中的FAQ:用结构化数据标记FAQ。

为此添加JSON-LD结构。
你想自动做吗,
Batista还写了一篇文章:为SEOs编写的现代JavaScript入门教程。
森摩尔网络从2013年开始做外贸网站的SEO推广服务,到现在已经7年多了。我们已经为上千个人和企业提供外贸网站的优化推广服务,客户遍及全国各地,我们的服务深受客户好评!如果您有外贸网站需要推广,请联系我们,我们会提供专业、快速的额服务!






