
- A+


找到没有链接的网页是困难的,但并非不可能。
如果你的网站上有用户和搜索引擎无法访问的页面,这是一个你需要解决的问题。
快。
这些类型的页面有一个名称:孤立页面。
在这篇文章中,你将了解什么是孤立页面,为什么修复它们对搜索引擎优化很重要,以及如何找到你网站上的每一个孤立页面。
什么是孤儿页(Orphan Page)
没有任何链接的页面称为孤立页。
像谷歌这样的搜索引擎通常通过以下两种方式之一找到新页面:
- 爬虫程序跟踪来自另一个页面的链接
- 爬虫程序会找到XML站点地图中列出的URL
所以,如果你想让谷歌抓取和索引你的网页,他们需要能够找到它。
为什么孤立页面是一个搜索引擎优化问题
搜索引擎无法通过链接找到孤立页面,因此孤立页面通常未编制索引,并且永远不会出现在搜索结果中。即使您的孤立页面列在XML站点地图中,它们仍然是SEO的一个问题。
孤立页不好吗
孤立页面对用户和爬虫来说都不是什么好东西。
用户无法通过站点的自然结构访问这些页面,因此如果这些页面上有重要或有用的信息,那么这些信息就是浪费。
这会造成令人沮丧的用户体验。
没有内部链接,就没有权力传递给页面,搜索引擎也没有语义或结构上下文来评估页面。
如果不知道页面在整个站点中的位置,就很难确定页面与哪些查询相关。
孤立页与死胡同页
在深入研究孤立页面之前,让我们花一点时间来简要澄清两个可能导致融合的SEO术语之间的差异。
正如我们已经建立的,孤立页面是一个网页,它不能被同一网站上的任何其他页面链接或访问。
另一方面,死胡同是一个网页,它没有链接到任何其他内部网页或任何外部网站,从而形成了一个“死胡同”
当人们登陆这个页面时,他们要么反击要么干脆放弃网站。
当搜索引擎爬虫登陆页面时,他们无处可去,也无法传递链接权益。
今天,有这么多模板和主题可用,创建一个死胡同更困难,但几乎不可能。
通过向页面内容添加链接,或者确保在每个页面上填充侧栏或页脚导航,可以很容易地修复死角。
一切正常,很好。
现在让我们找到你的孤儿页。
1、识别可爬网的页面
您需要一个列表,列出当前通过抓取站点链接可以访问的所有url。
你需要你自己的爬虫-一个搜索引擎优化蜘蛛,这样做。尖叫蛙是个不错的选择。
无论您使用什么爬虫程序,请确保它设置为只对搜索引擎可索引的页面进行爬网。
我的意思是,它不应该抓取以下页面:
- 不确定
- 通过搜索引擎隐藏机器人.txt一
从网站主页开始爬网。
确保使用规范的URL,包括正确的https或http,以及www或non-www。
完成站点爬网后,将URL导出到电子表格中,如下所示:
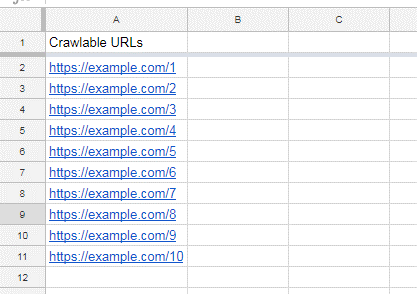
2、解决孤立页的两个常见原因
有两个常见的原因,孤儿页应该立即解决和处理。
这两个原因本质上都是页面重复,应该自动一致地重定向到一个URL。
如果没有,则很可能页面的某些版本没有链接,结果是孤立的。
在这种情况下,他们是孤儿并不是主要问题,他们是重复的事实是。
这些问题可能会在以后你寻找孤立页面时出现,需要处理,所以最好事先把它们放在一边。
非规范https/http或www/Non-www
理想情况下,站点上的每个公共页面都应该一致地使用http或https(最好是https),并且一致地使用www或non-www。
如果您的网站的所有变体都在您的浏览器中输入:
所有四个变体都应该自动重定向到完全相同的URL。
为了保持一致性,该页面本身应该是规范的。
如果这些变体中的一个没有正确地重定向,它可能是在更广泛的站点上出现类似问题的迹象。
使用这种变体检查其他url,看看这是否是一个更普遍的问题。
您应该测试站点的其他页面,并检查站点的.htaccess文件,以确保这些页面的重定向设置正确。
下面是如何在.htaccess中强制使用https。如果您这样做谷歌国外推广,请验证站点上的每个页面都具有SSL功能,否则您的用户将收到可怕的浏览器警告。
下面是如何强制www或非www。再次验证这不会造成任何服务器错误。
尾随斜杠
另一个需要注意的是尾部斜杠的一致使用。
例如,这两个URL可能生成相同的内容,但URL不完全相同:
检查站点上的一些页面,无论是否有尾随斜杠,确保它们自动重定向到同一个URL,并且始终这样做。
验证是否在.htaccess中正确设置了此项。
下面是如何在.htaccess中强制使用尾随斜杠。
3、从Google Analytics获取URL列表
根据定义,爬虫程序很难找到孤立页面。
因此,使用任何搜索引擎优化工具来寻找一个肯定是有问题的。
开始寻找孤立页面的最好地方之一是你自己的谷歌分析数据(或你使用的任何其他分析软件包)。
只要有问题的页面安装了Google Analytics,如果这个页面曾经被访问过,那么Google Analytics的某个地方就会有它的记录。
要获得URL的全面列表,请从左侧边栏转到Behavior>;Site Content>;All Pages。
因为我们的孤儿网页很难找到,他们被访问的次数可能相当少。
单击“Pageviews”使箭头指向上,表示uri列表按升序排序,从最小页面视图到大多数页面视图。
这会将最有可能成为孤立项的页面移到顶部:

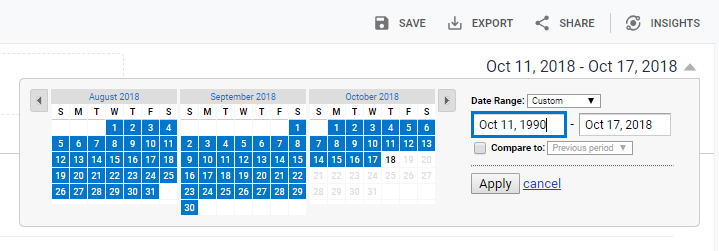
为了确保我们的列表尽可能全面,请转到右上角的日期范围。
将开始日期设置回Google Analytics之前的时间,然后单击应用按钮:
现在我们需要尽可能多地扩展url列表。
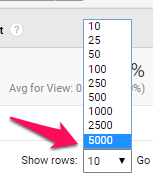
在右下角,单击显示行下拉菜单并选择最大行数。
我们最大的障碍是,分析一次最多只能列出5000个网址:
如果你有超过这个,你将不得不一次导出5000个页面,直到你有你的所有谷歌分析访问者数据。
然而,我们是按升序对页面浏览量进行排序的,所以我们的列表应该包括所有的,并且很可能包括大多数有访问者的孤立url。
分析可能需要一点时间来获取所有数据。
耐心一点,不要着急,否则你会有崩溃你的浏览器的风险。
加载URL后,请转到右上角,选择“导出”,然后导出Google工作表、Excel文件或CSV电子表格以获取URL。
如果你的技术水平稍微高一点,你可以使用googleanalytics API来加速这个过程;尝试使用pageviews度量来对比pagePath维度。
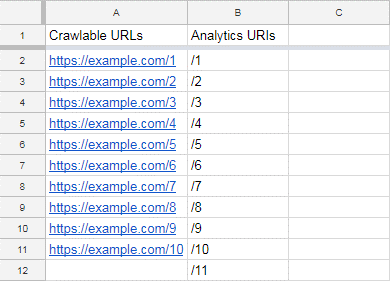
现在,将导出的分析文件中的URL复制到孤立页电子表格中,如下所示:
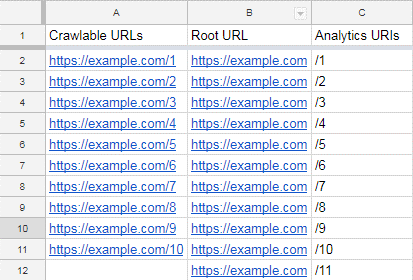
我们需要将这些转换成URL格式,以便它们有用。
为此,请插入新列并粘贴主页URL,如下所示:
并使用concat()公式将它们组合成下一列中的URL:
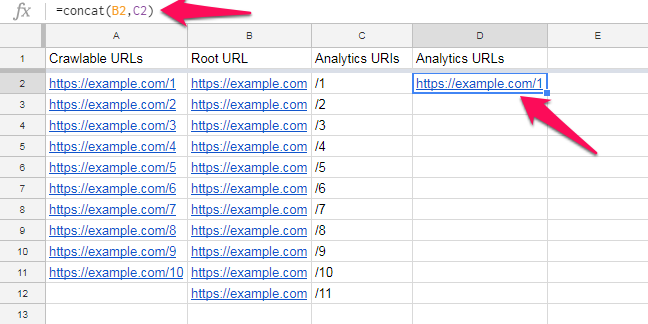
然后,只需向下拖动公式即可获得完整的URL列表:
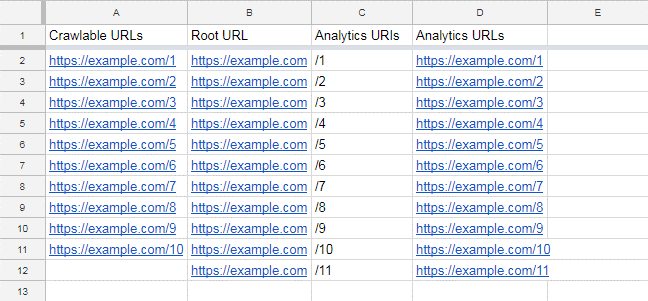
4、确定你的孤立网址
为了识别孤立的url,我们需要比较电子表格中可爬网url列表和找到的分析url列表。
在我们假设的例子中,https://example.com/11是一个孤立的页面,但实际上您几乎总是有更多的url需要筛选,我们需要自动化识别孤立url的过程。
为此,我们需要一个公式来检查分析列表中的每个URL是否也在我们的可爬网URL列表中找到英文网站优化排名。
下面是一个公式示例,可以实现这一点:
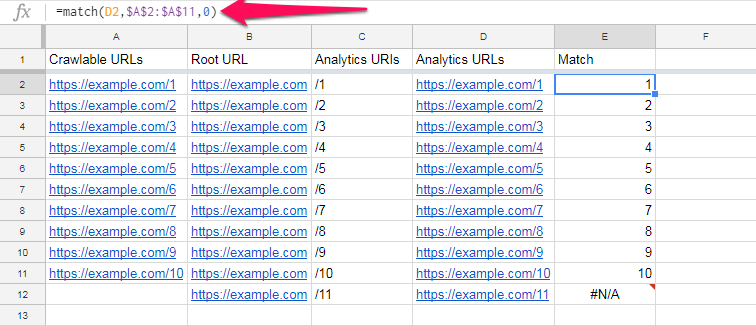
我们在单元格E2中使用的“匹配”公式如下:
=匹配(D2,$A$2:$A$11,0)
此公式检查单元格D2中的URL是否在$A$2:$A$11范围内。
(如果您对电子表格不太熟悉,这里有美元符号,以确保当我们将公式拖到列中时,范围不会改变。)
值“0”告诉googlesheets这些列不需要排序。(请参阅Google Sheets文档。)
如果存在匹配项,则公式将返回其在范围中的位置,在本例中,该位置是范围中的第一个位置。
我们更感兴趣的是,如果没有匹配的。
如您所见,对于https://example.com/11,因为在我们的可爬网URL列表中找不到它。







